Radix Tree 를 이용한 정적 문자열 테이블 탐색
텍스트 문서에서 문자열을 읽어 이 문자열에 해당하는 숫자를 찾아 반환하는 코드를 만드는 일이 가끔씩 있다. 예를 들면 다음과 같은 함수를 들 수 있다.
int parse(const char* s) {
return
s == "apple" -> 1
s == "apps" -> 2
s == "bana" -> 3
s == "banana" -> 4
else -> -1
}
이 함수가 하는 일을 일반화 하면 “고정된 문자열 → 값 테이블”에서 주어진 문자열에 해당하는 값을 찾는 일이라고 볼 수 있다. Enum 타입의 멤버 이름 → 상수를 매핑하는 작업도 이에 해당한다.
이런 작업은 동적인 테이블과 마찬가지로 다음과 같은 방법을 쓸 수 있다.
- 문자열 키로 정렬되어 있는 배열에서 이진 탐색
- std::map<string, T>.find
- std::unordered_map<string, T, hash<string>>.find
모두 좋은 방법이지만 정적인 테이블이라는 특성을 활용해보면 어떨까 하는 생각에 Radix Tree 를 이용해 문자열 탐색을 하는 코드를 작성해 보았다.
Radix Tree
먼저 위에서 예로 들었던 문자열 테이블을 Prefix Tree 로 표현해보면 다음과 같다. (Prefix Tree 는 테이블의 문자열을 받아들이는 DFA 와 비슷하게 생겼다.)
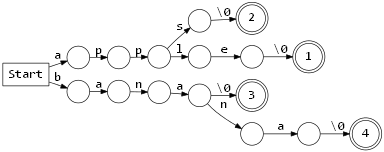
구성한 Prefix Tree 에서 자식이 1개인 노드들을 합쳐서 하나의 노드로 줄이면 다음과 같은 Radix Tree 를 만들 수 있다.
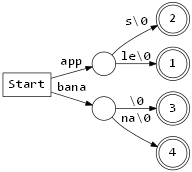
Radix Tree 로 바로 코드를 만들 수 있는데 하기 전에 Radix Tree 를 살짝 변형해보자. “노드 분기는 문자로만 한다.” 라는 제약을 만족시키는 Radix Tree 는 다음과 같다.
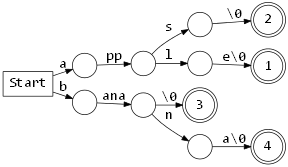
문자로만 분기를 허용하는 이유는 switch 문을 사용하기 위해서다. 이제 얻어진 수정된 Radix Tree 를 가지고 parse 문을 만들어 보자.
코드 생성
만든 Radix Tree 는 간단하게 구조화 된 코드로 변환할 수 있다. 아래와 같은 단순한 룰로 parse 코드를 생성할 수 있다.
- 문자 분기는 switch 문으로 비교 분기
- 문자열 확인은 str[n]cmp 함수 사용
- 하위 노드로 진입할 때 코드 블럭 열기
- 마지막 노드까지 진입했으면 해당 값을 return. 노드에서 분기/비교에 실패할 때는 -1 을 return.
생성 룰을 통해 앞서 구성한 Radix Tree 로 부터 다음과 같은 코드를 만들 수 있다.
int parse(const char* s) {
switch (s[0]) {
case 'a': if (!strncmp(s+1, "pp", 2))
switch (s[3]) {
case 'l': if (!strcmp(s+4, "e")) return 1; else return -1;
case 's': if (s[4] == 0) return 2; else return -1;
default: return -1;
}
else return -1;
case 'b': if (!strncmp(s+1, "ana", 3))
switch (s[4]) {
case 0: return 3;
case 'n': if (!strcmp(s+5, "a")) return 4; else return -1;
default: return -1;
}
else return -1;
default: return -1;
}
}
길이 분기가 추가된 코드 생성
위 코드에서 str[n]cmp 대신 memcmp 를 써보자. memcmp 가 str[n]cmp 보다 컴파일러에 의한 최적화될 여지가 많기 때문이다. 하지만 위 parse 함수는 당장 memcmp 를 사용할 수 없다. 문자열 s 의 길이를 알 수 없기 때문이다.
이를 해결하기 위해 맨 처음 단계에 입력받은 문자열의 길이를 확인해 분기하는 단계를 넣어보자. 앞서 생성한 Redix Tree 의 처음 부분에 길이를 확인하는 단계가 추가된다. 또한 길이 확인이 되었으므로 마지막 단계에 있었던 null 문자 확인 단계가 제거된다. 길이 분기가 추가된 Tree 는 다음과 같다.
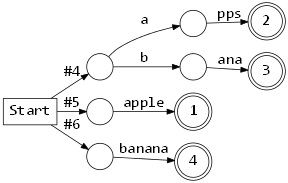
이 Tree 로 부터 코드 생성 룰은 앞서 만든 것과 유사하다. str[n]cmp 대신 memcmp 를 사용하고 첫 분기에 문자열 길이를 확인 하는 정도다. 이 룰에 따라 코드를 만들면 다음과 같다.
int parse(const char* s, size_t len) {
switch (len) {
case 4:
switch (s[0]) {
case 'a': if (!memcmp(s+1, "pps", 3)) return 2; else return -1;
case 'b': if (!memcmp(s+1, "ana", 3)) return 3; else return -1;
default: return -1;
}
case 5: if (!memcmp(s+0, "apple", 5)) return 1; else return -1;
case 6: if (!memcmp(s+0, "banana", 6)) return 4; else return -1;
default: return -1;
}
}
여기서 입력 문자열 s의 길이 len을 함수 인자로 추가했다. parse 함수 안에서 strlen 으로 길이를 구하지 않는 이유는 함수 호출 전에 이미 len 을 알고 있는 경우가 많기 때문이다. 예를 들어 전체 텍스트에서 delimiter 에 의해 구분된 문자열을 입력으로 받는 경우 이미 delimiter 에 의해 길이를 알 수 있고 애초에 std::basic_string 과 같이 길이를 사전에 알고 있는 클래스를 사용할 수도 있기 때문이다.
참고로 주어진 테이블 데이터를 파싱하는 함수를 만드는 소스는 python 으로 만들었으며 RadixMaker 에 올려두었다.
성능 측정
테스트 데이터는 다음과 같이 총 3가지를 대상으로 했다.
- D-4: 앞서 예로든 데이터. (apple, apps, bana, banana)
- D-16: 기본 16 컬러 값의 영문 이름. (silver, gray, …, yellow, cyan)
- D-118: 화학 원소 이름. (Hydrogen, Helium, …, Ununseptium, Ununoctium)
테스트 알고리즘은 다음과 같이 총 8가지를 대상으로 했다.
- strlen: 주어진 문자열의 길이만 측정하는 baseline 측정용 알고리즘
- sorted_vector: 정렬된 std::vector에 대해 std::lower_bound 를 이용한 이진 탐색 알고리즘
- map: std::map 의 find 탐색 알고리즘
- unordered_map: std::unordered_map 의 find 탐색 알고리즘 (hash function: sdbm)
- static: Radix Tree 에 대해 코드 생성된 탐색 알고리즘
- static_len: static 에 길이 분기가 추가된 알고리즘
- dynamic: Radix Tree 에 대한 코드 생성이 아닌 일반 탐색 알고리즘
- dynamic_len: dynamic 에 길이 분기가 추가된 알고리즘
테스트 환경은 다음과 같다.
- CPU: Intel Core i5-3550 3.3GHz
- OS: Windows 7 Pro SP1
- Compiler / Build: Visual C++ 10 / Builtin Release
테스트는 다음과 같이 했다.
- 데이터에 포함된 문자열을 순서대로 탐색을 해 걸린 시간을 평균냄. 따라서 항상 탐색이 성공하는 경우만을 대상으로 한다.
측정 결과는 다음과 같다. 걸린 시간의 단위는 µs.
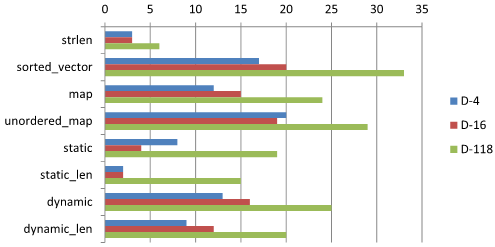
결과 해석
- 데이터를 보면 Radix Tree 를 구현한 static, dynamic 모두 괜찮은 성능을 보인다.
- 길이 분기가 추가된 Radix Tree 인 static_len, dynamic_len 의 속도가 그렇지 않은 static, dynamic 보다 빠르다. memcmp 최적화가 잘 됨을 알 수 있다.
- 코드 생성을 기반으로 한 static_len 의 속도가 상당히 빠른데 D-4, D-16 데이터의 경우 strlen 보다 빠른 것을 알 수 있다.
- 코드 생성인 static, static_len 은 D-118 과 같이 큰 테이블에서는 상대적으로 성능이 떨어지는 것을 볼 수 있다. 이는 데이터에 비례해 코드 양이 늘어나기 때문에 발생하는 것으로 추정된다.
- unordered_map 은 map 보다 항상 느린 것을 알 수 있다. 데이터가 충분히 크지 않으면 map 이 문자열 탐색에서는 성능 우위가 있음을 알 수 있다.
- sorted_vector 는 기본적으로 map 과 동일한 성능을 보여야 하는데 생각보다 느리게 나왔다. 이는 컴파일러가 map find 코드를 좀 더 잘 최적화해 줘서 인것으로 보인다. Debug 빌드에서는 sorted_vector 가 좀 더 나은 성능을 보인다.
변형된 테스트를 한 번 더 했다.
- D-118 데이터에 포함된 문자열을 하나만 잡고 그것만 탐색을 해 걸린 시간을 평균냄.
측정 결과는 다음과 같다. 걸린 시간의 단위는 µs.
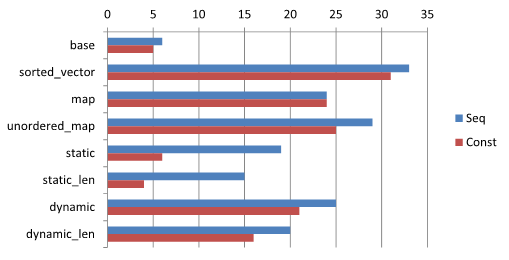
결과 해석
- 대부분 앞선 테스트와 이번 테스트의 결과가 비슷하다. 이는 입력 데이터가 어떤 패턴을 보여도 비슷한 성능을 보임을 의미한다.
- 단 static 과 static_len 은 드라마틱하게 빨라지는 것을 볼 수 있다. 이는 특정 path 로만 parse 함수가 실행되고 CPU 에 의해 분기 예측이 잘 맞아 떨어지는 경우가 많기 때문으로 보인다.
결론
고정된 문자열 테이블에서 문자열을 탐색하는 함수를 Radix Tree 를 이용한 코드 생성으로 구현해 보았다. 기대보다 빠른 성능을 보여 빠른 성능이 필요한 부분에 쓸만한 것으로 보인다. 특히 다음과 같은 조건 아래에서 성능이 좋게 나오니 참고하면 좋을듯.
- 테이블의 크기가 크지 않은 경우. (n < 100)
- 테이블의 크기가 큰 경우라도 입력 문자열의 분포가 편향된 경우.
가독성이나 유지보수성은 일반 컨테이너 클래스를 사용한 탐색에 비해 떨어지니 꼭 필요한 곳에만 쓸 것.